Students normally gets confused in Difference between Process and Thread
What is a Process?
If you are a programmer, you create a program by writing a code and when you run that program it becomes a process. It is very important to have a clear difference between a program and a process because one program can produce many running processes that are just different versions of a single program. It is a kind of an object-oriented programming language, where you have one class and from that class you can create many objects of the same class.
Components Involved
So, when it comes to run programs in the system, there are three main components: CPU, Random Access Memory and Memory Controller which acts as an interface between CPU and RAM. When only one program is running in the system, then life is simple because all of the CPU time is given to that program and all the RAM is given to that program; really easy, but when we want to run multiple programs things become complicated because the CPU time and memory has to be divided amongst programs. How does the kernel do that well, is where we get an idea of a process. Process is a logical container which holds all the information about each of the processes running in your system as shown in Figure 1.
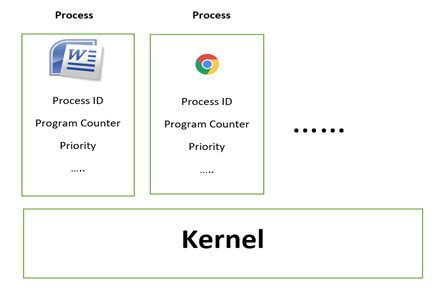
Figure-1 Processes running in the system
Kernel divides the CPU time among the different processes in the memory by switching between processes. This switching occurs in milliseconds just like a cartoon where it shows one frame after the other very quickly and gives us the idea of animation. Similarly switching among processes happens very quickly gives us the appearance that processes are running in parallel.
To achieve concurrency of execution of among processes or parts of a process system either creates multiple processes or threads. There are parts of the program where performance of the program can be improved using threads.
Memory Layout of Process
Considering UNIX/Linux platform, different processes are created using fork() system call. Fork() system call duplicates the process and creates a child process. The newly created process has its own address space in the memory with separate space for data, code , stack and registers. Figure-2 and Figure-3 shows the layout of process in the memory before and after fork() is called.

Figure-2 Layout of a process in the memory
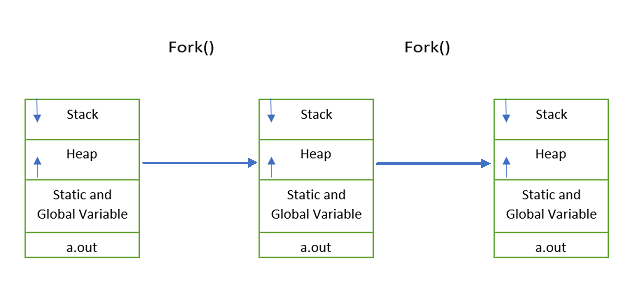
Figure-3 Process get replicated when fork is called
How a process is created using fork()?

The fork() system call will create a process which is a copy of the main process. So the output of the above code is:

What is a Thread?
On the other hand, thread is a sequence of instructions within a program that can be executed independently of other code. Threads contain only necessary information like stack (local variables, functions, return values), a copy of registers and any thread specific data to allow them to schedule individually. Other data is shared between all the threads of a process as shown in Figure-4.
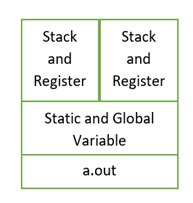
Figure 4 Threads in Memory
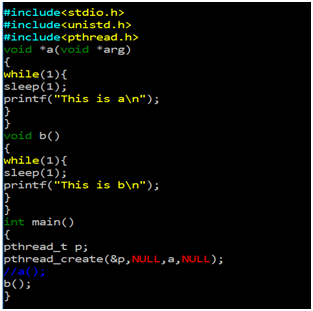
What is the need of thread? Let’s learn it with a simple code

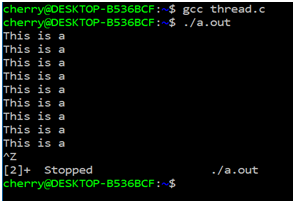
The above code consists of two functions a and b. When we execute the above-mentioned code, what will happen? It will run only function a as seen in the output below. The reason is indefinite while loop. How can we run both the functions? One solution to run both of them together is implementation of threads within the code.
The above code is modified by applying threads in it using pthread_create().
Output
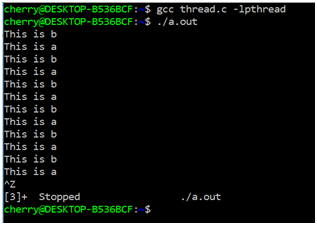
Now we can see both the functions are running parallelly with the implementation of the=reads in it. What if we want to run the above code for finite number of times? We will replace the while loop with a for loop.

The function a will run for 5 times and function b will run for 3 times. When we execute the above code the output will be :

As we can see, the code gets executed for 3 times, as per the loop mentioned in function b. The reason behind this is the main process gets executed faster than the thread and will exit after execution. To overcome this problem, main process should wait for thread to get executed first. This can be done using library function called pthread_join().

Output

Conclusion
The table below summarizes the comparison between process and thread
|
|
|
| Processes are heavy-weight task | Threads are light-weight task because of the fact that they do not replicate everything in the memory address. |
| Processes are created using system calls, therefore kernel intervention is required. | Threads are created using thread library, minimal kernel intervention is required. These are user-level threads. |
| Operating system treats different processes differently. | All user-level threads of a process are treated as single task for operating system. |
| Data, code, stack and registers are different for different processes. | Threads share data and code but stack and registers are specific for each thread. |
| Context switching is slower | Context switching is faster |
| Blocking a process will block that individual process. It will not block the other processes. | Blocking a process will block the entire process including threads and vice versa. |
| Independent | Interdependent |